This parameter enables compression on master/slave protocol. If both master and slave supports it, this parameter will instruct MariaDB/MysQL to use compression.
This parameter is not enabled by default.
It can be enabled in your my.cnf file (ensure to restart the DB service after enabling it to take effect)
Replication was single threaded in MariaDB 5.5 and MySQL 5.5. The previous transaction must commit on the slave before the next transaction can start.
A single I/O thread works to replicate events from the Master’s binlog to the relay log in the Slave.
On the Slave, the SQL Thread will apply those events, one after the other.
With that said, as you can imagine, replication can sometimes lag. Being single threaded, it is challenging to keep the Master and Slave in sync.
Enable Parallel Slave
To enable, indicate slave-parallel-threads=# in your my.cnf.
Configure the number (#) of worker threads to apply events in parallel for all your slaves.
If you indicate a value of zero, then that means no worker threads are created.
The value should be at least twice the number of multi-source master connections utilized.
You do not have to restart mysqld when you configure slave-parallel-threads=#, because it is a dynamic variable. However, all slaves connections must be stopped when modifying the value.
Here is a link that shows the performance improvement when using parallel replication.
Waiting for prior transaction to start commit before starting next transaction
The previous batch of transactions that committed together on the master has to complete first
Waiting for prior transaction to commit
Transaction has been executed by the worker thread
Parallel Slave Queue Size
SQL thread will read ahead in the relay logs when parallel replication is used. This will queue events in memory while looking for opportunities for executing events in parallel. The system variable that sets a limit for how much memory it will use for this is slave_parallel_max_queued
In order for the SQL thread to read far enough ahead in the binary log to exploit all possible paralellism, the slave_parallel_threads system variable should be set large enough.
To prevent limit throughput, the slave_parallel_max_queued system variable could be set relatively high. It should just be set low enough that total allocation of the parallel slave queue will not cause the server to run out of memory.
Slave Parallel Mode
There are 2 options for Slave Parallel Mode: In-Order and Out-of-Order
In-order runs transactions in parallel, but instructs the commit steps of the transactions in the precise same sequence as on the master.
Out-of-order will have the ability to execute and commit transactions in a different order on the slave than primarily on the master. The application must be tolerant to viewing updates occur in random order.
In this blog post, we are going to discuss MariaDB crash issues due to out-of-memory (OOM), and how to troubleshoot them.
When you get this error, it clearly indicates that the server is running out of memory. In other words, the allocated memory to MariaDB is not enough to handle the process requirements.
If memory is insufficient, then we just have to increase RAM, right? Well, this is certainly one solution, but it is the easiest way out. Simply adding RAM is neither the ideal solution nor a cheaper way. A memory-intensive query or process can eventually eat up the added memory, and can lead to errors in a short span of time.
Common Causes of Out-Of-Memory Issues
Non-optimal tables and queries
MySQL Server Configuration
Memory-intensive processes
Poor hardware resources
Insufficient RAM
Lack of disk space
Here are the ways to troubleshoot
Check Linux OS and Config
Check /var/log/messages and /var/log/syslog. Try to find an entry where it says something like “OOM killer killed MySQL”. Once you find it, the surrounding details will give you clues.
Check available RAM.
free -g
cat /proc/meminfo
Issue “top” command to see what applications are consuming RAM.
Run vmstat 5 5 to view if the system is swapping and if it is reading/writing via virtual memory.
Check MariaDB. Look for possible MariaDB memory leaks
These are the places where MariaDB allocates most of the memory:
Table cache
InnoDB (execute show engine innodb status, and look for buffer_pool and associated caches in the buffer pool section.
Identify if there are temporary tables in RAM (select * from information_schema.tables where engine=’MEMORY’;)
Prepared statements, when it is not removed from the set of resources (show global status like ‘Com_prepare_sql’; show global status like ‘Com_dealloc_sql’)
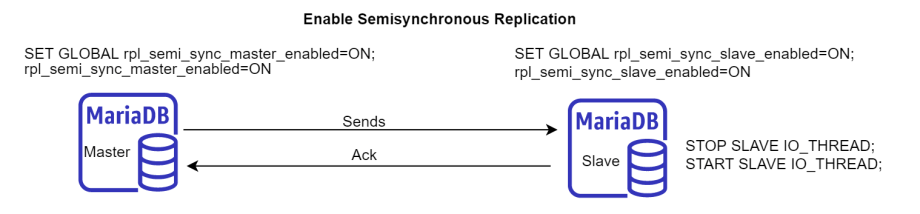
In this blog post, we are going to learn how to enable Semisynchronous Replication in MariaDB.
MariaDB provides semisynchronous replication option besides the standard MariaDB asynchronous replication.
In Asynchronous replication, the Master does not wait for a slave to confirm that an event has been received whenever the slave request events from the Master’s binary log.
Semisynchronous Replication
The procedure to enable Semisynchronous Replication below applies only to MariaDB 10.3.3 and later since it is already built into MariaDB server and is no long provided by a plugin.
It can be set dynamically with SET GLOBAL.
SET GLOBAL rpl_semi_sync_master_enabled=ON;
It can also be set in my.cnf
[mariadb]
...
rpl_semi_sync_master_enabled=ON
To enable Semisynchronous Replication on the Slavedynamicallywith SET GLOBAL.
SET GLOBAL rpl_semi_sync_slave_enabled=ON;
It can also be set in my.cnf
[mariadb]
...
rpl_semi_sync_slave_enabled=ON
If slave threads are already running when you enable Semisynchronous Replication, you need to restart slave I/O thread. Otherwise, it will continue to use asynchronous replication.
STOP SLAVE IO_THREAD;
START SLAVE IO_THREAD;
Configuring the Master Timeout
In semisynchronous replication, the slave acknowledges the receipt of the transaction’s events only after the events have been written to the relay log and flushed.
A timeout will occur if the slave does not acknowledge the transaction before a certain amount time, and the Master will be switching to Asynchronous replication.
Rpl_semi_sync_master_status status variable will be switched to OFF when this happens.
Semisynchronous replication will be resumed when at least one semisynchronous slave catches up, and at the same time Rpl_semi_sync_master_status status variable will be switched to ON.
The timeout period is configurable. It can be changed by setting the rpl_semi_sync_master_timeout system variable.
In this blog post, we are going to talk about the variable InnoDB_flush_log_at_trx_commit. We are going to discuss what each value that we can assign to this variable means, and how it can affect performance and durability.
Innodb_flush_log_at_trx_commit controls the durability in ACID compliance
A – atomicity
C – consistency
I – isolation
D – durability
The possible values for this variable is 0, 1, and 2.
The specific path of the query goes to the innodb buffer pool, then log buffer (redo logs), then OS buffer, then finally to log file.
When innodb flush log at transaction commit is set to 0, your write goes thru memory, thru the buffer pool into the log buffer. That write then flushes from the log buffer to the log file on disk for every 1 second or when the OS flushes.
If this variable is set to 1, which is maximum durability. Your write goes to the log buffer, but the commit of the file ensures that it is written all the way on disk. This value will have a bit of performance hit compared to value 0.
If the value is set to 2, the write goes to the log buffer, but the file will be committed all the way to the OS buffer. And then the OS will flush to disk roughly every 1 second.
Advantages and Disadvantages
0 – when the database crashes, the log buffer within memory will get loss, and there is a possibility of losing those transaction. This setting is for performance, but not for durability.
1 – every write will surely be written to the redo log on disk. You will not lose that write regardless of the crash.
2 – You will lose only about 25% performance as compared to 1. If the DB crashes, the file is still written to disk cache, and then written to disk later. But if the DB server itself crashes, that DB server’s disk buffer may lose its data. This can be prevented though if we have battery backup or SAN.
Undo log is used to keep track of changes performed by active transactions and roll them backup if necessary. It is physically stored in the system table spce and, optionally, in other tablespaces.
Redo log tracks data of the requested data changes and is used to recover tables after a crash. It is physically stored in dedicated files.
Redo and Undo logs are both used during crash recovery.
In our environment where we have thousands of MariaDB servers, 95% of the reason why replication is slow or lagging is because there are many tables that do not have primary key.
Below is an example of what we can see in show processlist when the SQL Thread is lagging because many tables do not have primary keys.
Below is a script to check tables that do not have a primary key.
SELECT tables.table_schema,
tables.table_name,
tables.table_rows
FROM information_schema.tables
LEFT JOIN (SELECT table_schema,
table_name
FROM information_schema.statistics
GROUP BY table_schema,
table_name,
index_name
HAVING Sum(CASE
WHEN non_unique = 0
AND nullable != 'YES' THEN 1
ELSE 0
end) = Count(*)) puks
ON tables.table_schema = puks.table_schema
AND tables.table_name = puks.table_name
WHERE puks.table_name IS NULL
AND tables.table_schema NOT IN ( 'mysql', 'information_schema',
'performance_schema'
, 'sys' )
AND tables.table_type = 'BASE TABLE'
AND engine = 'InnoDB';
Using the script above, I counted how many tables do not have primary key, and found out that there are 64 tables.
Having a primary key should be the norm/best practice in terms of designing schema anyway.
We have to ensure all our tables have primary key. This will guarantee that all rows are unique, and it will make the SQL thread locate rows to delete (or update) easily.
If there is no way to logically add a natural primary key for the table, a potential solution is to add an auto-increment unsigned integer column as the primary key.
The Doublewrite Buffer provides a copy of a page needed to recover from a page corruption. This kind of corruption can happen when there is a power failure while InnoDB is writing a page to disk. InnoDB can track down the corruption from the mismatch of the page checksum while reading that page.
InnoDB writes a page to the doublewrite buffer first whenever it flushes page to disk. InnoDB will write the page to the final destination only when the buffer is safely flushed to disk. When recovering, InnoDB scans the double write buffer and for each valid page in the buffer, and checks if the page in the data file is valid too.
In this blog post, I will be showing you the commands that we can use to do streaming backup using mbstream, and how to redirect the stream to a slave , which can be useful especially when you have insufficient disk space in the Master server to hold multiple copies of backup images.
To redirect backup stream to a slave server, we use the socat utility.
Socat stands for Socket Cat. It is a relay for bidirectional data transfer between two independent data channels.
You can install socat using the command below
yum install -y socat
This is the first command that we will execute in Slave.
The –compress-threads option defines the number of worker threads to use in compression. It can be used together with –parallel option. In the example above, we use –parallel=4, and –compress-threads=12. This means that it will create 4 I/O threads to read the data; then pipe it to 12 threads for compression.
When we execute the mariabackup command in the Master, below is what we will observe in slave. We will see that it is starting to do data transfer.
When the backup finishes, we will see that it exits with status 0.
In this blog post, I’m going to show you how to setup GTID replication using Mariabackup.
There are 2 main benefits of using global transaction:
Failover is easier than with file-based replication.
the state of the slave is recorded in a crash-safe way.
Here are the general steps:
Enable binary logging on the master
Enable GTID
Create a replication user on the master
Set a unique server_id on the slave
Take backup from the master
Restore on the slave
Execute the CHANGE MASTER TO command
Start the replication
1. Ensure that the server_id value and bind_address are configured differently in my.cnf in each of the server
that will be part of the replication.
In this example, we will configure a 2 node master-slave setup. The bind-address is the hostname IP.
vi my.cnf
In Master:
server_id=1
bind-address=192.168.1.115
In Replica:
server_id=2
bind-address=192.168.1.131
2. Enable binary logging and GTID strict mode in both servers
show global variables like 'log_bin';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| log_bin | ON |
+---------------+-------+
show global variables like '%gtid_strict_mode%';
+------------------+-------+
| Variable_name | Value |
+------------------+-------+
| gtid_strict_mode | ON |
+------------------+-------+
If bin logging is not enabled, you may do so by adding the line below in my.cnf
log-bin = db1-bin
# Or specify an different path
log-bin = /mariadb/bin/logs/bin_logs/bin_log
Restart DB service for the change to take effect.
sudo service mysql stop
sudo serivice mysql start
If gtid is not enabled, add the line below in my.cnf, then enable it globally.
Add this line in cnf
gtid_strict_mode=1
Login to MariaDB, then set global_script_mode=1.
set global gtid_strict_mode=1;
3. Create a user in Master.
The replica is going to use this user connection to read the binary logs on the master and then put those into the relay logs on the replica.
CREATE USER 'repl'@'%' IDENTIFIED BY 'P@$$w0rd';
GRANT RELOAD, SUPER, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'repl'@'%';
4. Install qpress (As root) in both Master and Slave for compression/decompression.
6. In Replica, create a directory where we will place the backup from Master
mkdir -p /mariadb/backup/rep
7. In Master, use scp to transfer the entire backup image to the replica.
# Go to the directory where you placed the backup
cd /mariadb/backup
scp -rp full_backup mysql@192.168.1.131:/mariadb/backup/rep
8. In Replica, Stop DB Service
sudo service mysql stop
# Verify that DB service has been stopped
ps -ef| grep mysqld
9. In Replica, Remove all contents in Data Directory.
mkdir -p /mariadb/data/old_data
mv /mariadb/data/* /mariadb/data/old_data/
rm -rf /mariadb/data/old_data/
# Ensure that the data directory is empty
cd /mariadb/data
ls -la
10. In Replica, copy the backup image to data directory.